|
|
2 years ago | |
|---|---|---|
| assets | 2 years ago | |
| eval | 2 years ago | |
| examples | 2 years ago | |
| .gitignore | 2 years ago | |
| LICENSE | 2 years ago | |
| NOTICE | 2 years ago | |
| README.md | 2 years ago | |
| README_CN.md | 2 years ago | |
| demo.py | 2 years ago | |
| tech_memo.md | 2 years ago | |
README.md
![]()
Qwen-7B 🤖 | 🤗 | Qwen-7B-Chat 🤖 | 🤗 | Demo | Report
中文 | English
We opensource Qwen-7B and Qwen-7B-Chat on both 🤖 ModelScope and 🤗 Hugging Face (Click the logos on top to the repos with codes and checkpoints). This repo includes the brief introduction to Qwen-7B, the usage guidance, and also a technical memo link that provides more information.
Qwen-7B is the 7B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-7B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-7B, we release Qwen-7B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. The features of the Qwen-7B series include:
- Trained with high-quality pretraining data. We have pretrained Qwen-7B on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional damain data.
- Strong performance. In comparison with the models of the similar model size, we outperform the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.
- Better support of languages. Our tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.
- Support of 8K Context Length. Both Qwen-7B and Qwen-7B-Chat supports the context length of 8K, which allows inputs with long contexts.
- Support of Plugins. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.
News
- 2023.8.3 We release both Qwen-7B and Qwen-7B-Chat on ModelScope and Hugging Face. We also provide a technical memo for more details about the model, including training details and model performance.
Performance
In general, Qwen-7B outperforms the baseline models of a similar model size, and even outperform larger models of around 13B parameters, on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, HumanEval, and WMT22, etc., which evaluate the models' capabilities on natural language understanding, mathematic problem solving, coding, etc. See the results below.
| Model | MMLU | C-Eval | GSM8K | HumanEval | WMT22 (en-zh) |
|---|---|---|---|---|---|
| LLaMA-7B | 35.1 | - | 11.0 | 10.5 | 8.7 |
| LLaMA 2-7B | 45.3 | - | 14.6 | 12.8 | 17.9 |
| Baichuan-7B | 42.3 | 42.8 | 9.7 | 9.2 | 26.6 |
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 9.2 | - |
| InternLM-7B | 51.0 | 52.8 | 31.2 | 10.4 | 14.8 |
| Baichuan-13B | 51.6 | 53.6 | 26.6 | 12.8 | 30.0 |
| LLaMA-13B | 46.9 | 35.5 | 17.8 | 15.8 | 12.0 |
| LLaMA 2-13B | 54.8 | - | 28.7 | 18.3 | 24.2 |
| ChatGLM2-12B | 56.2 | 61.6 | 40.9 | - | - |
| Qwen-7B | 56.7 | 59.6 | 51.6 | 24.4 | 30.6 |
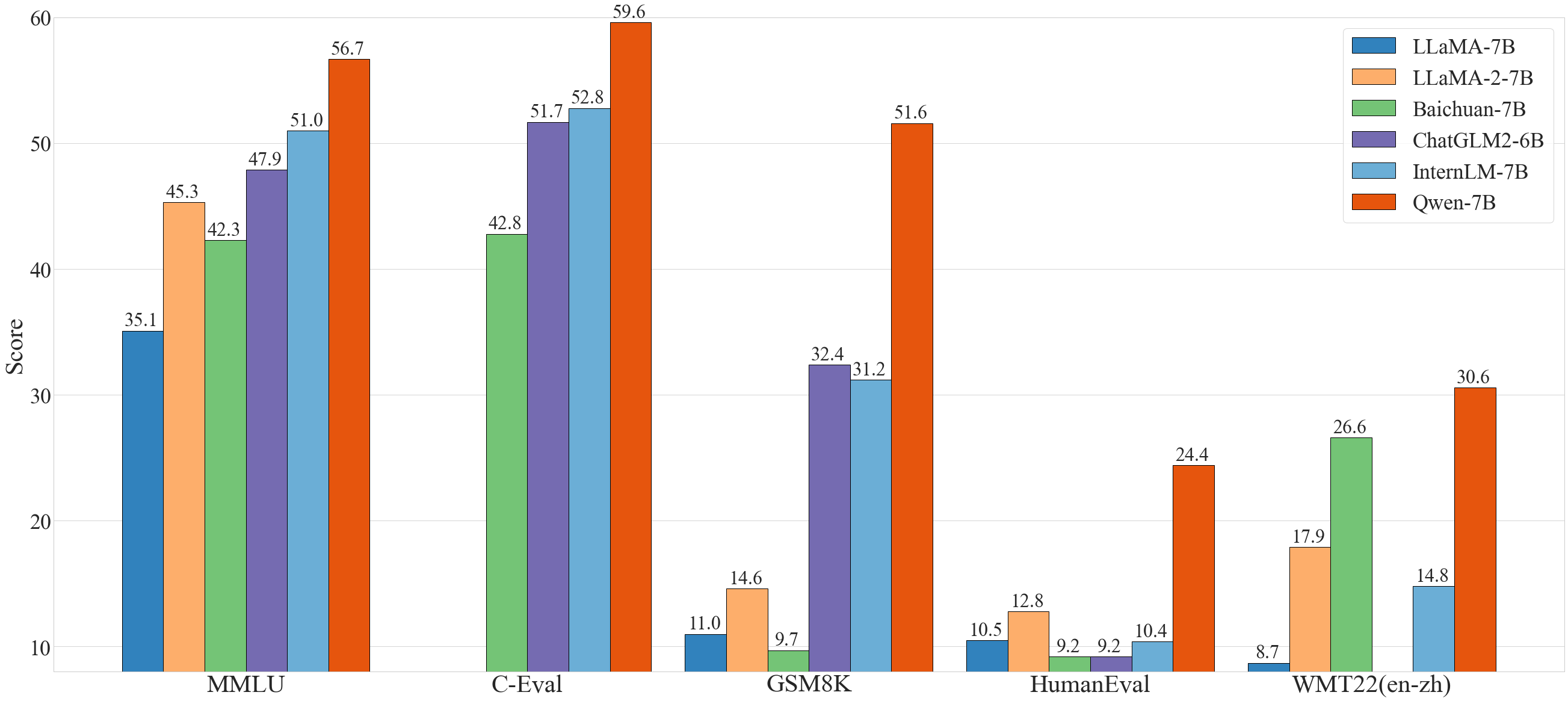
For more experimental results (detailed model performance on more benchmark datasets) and details, please refer to our techinical memo by clicking here.
Quickstart
Below, we provide simple examples to show how to use Qwen-7B with 🤖 ModelScope and 🤗 Transformers.
Before running the code, make sure you have setup the environment and installed the required packages. Make sure the pytorch version is higher than 1.12, and then install the dependent libraries.
pip install transformers==4.31.0 accelerate tiktoken einops
We recommend installing flash-attention for higher efficiency and lower memory usage.
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
Now you can start with ModelScope or Transformers.
🤗 Transformers
To use Qwen-7B for the inference, all you need to do is to input a few lines of codes as demonstrated below:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
Running Qwen-7B-Chat is also simple. We provide you with an example of IPython to show how to interactive with the model.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
>>> model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
>>> # 第一轮对话 1st dialogue turn
>>> response, history = model.chat(tokenizer, "你好", history=None)
>>> print(response)
你好!很高兴为你提供帮助。
>>> # 第二轮对话 2nd dialogue turn
>>> response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
>>> print(response)
这是一个关于一个年轻人奋斗创业最终取得成功的故事。
故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
>>> # 第三轮对话 3rd dialogue turn
>>> response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
>>> print(response)
《奋斗创业:一个年轻人的成功之路》
🤖 ModelScope
ModelScope is an opensource platform for Model-as-a-Service (MaaS), which provides flexible and cost-effective model service to AI developers. Similarly, you can run the models with ModelScope as shown below:
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope import snapshot_download
model_id = 'QWen/qwen-7b-chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision)
pipe = pipeline(
task=Tasks.chat, model=model_dir, device_map='auto')
history = None
text = '浙江的省会在哪里?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
text = '它有什么好玩的地方呢?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
Quantization
To load the model in lower precision, e.g., 4 bits and 8 bits, we provide examples to show how to load by adding quantization configuration:
from transformers import BitsAndBytesConfig
# quantization configuration for NF4 (4 bits)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=torch.bfloat16
)
# quantization configuration for Int8 (8 bits)
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map="cuda:0",
quantization_config=quantization_config,
max_memory=max_memory,
trust_remote_code=True,
).eval()
With this method, it is available to load Qwen-7B in NF4 and Int8, which saves you memory usage. We provide related statistics of model performance below. We find that the quantization downgrades the effectiveness slightly but significantly increases inference efficiency and reduces memory costs.
| Precision | MMLU | Memory |
|---|---|---|
| BF16 | 56.7 | 16.2G |
| Int8 | 52.8 | 10.1G |
| NF4 | 48.9 | 7.4G |
Tool Usage
Qwen-7B-Chat is specifically optimized for tool usage, including API, database, models, etc., so that users can build their own Qwen-7B-based LangChain, Agent, and Code Interpreter. In the soon-to-be-released internal evaluation benchmark for assessing tool usage capabilities, we find that Qwen-7B reaches stable performance.
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
|---|---|---|---|
| GPT-4 | 95% | 0.90 | 15% |
| GPT-3.5 | 85% | 0.88 | 75% |
| Qwen-7B | 99% | 0.89 | 8.5% |
For how to write and use prompts for ReAct Prompting, please refer to the ReAct examples. The use of tools can enable the model to better perform tasks.
Additionally, we provide experimental results to show its capabilities of playing as an agent. See Hugging Face Agent for more information. Its performance on the run-mode benchmark provided by Hugging Face is as follows:
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
|---|---|---|---|
| GPT-4 | 100 | 100 | 97.41 |
| GPT-3.5 | 95.37 | 96.30 | 87.04 |
| StarCoder-15.5B | 87.04 | 87.96 | 68.89 |
| Qwen-7B | 90.74 | 92.59 | 74.07 |
Long-Context Understanding
To extend the context length and break the botteneck of training sequence length, we introduce several techniques, including NTK-aware interpolation, window attention, LogN attention scaling, to extend the context length to over 8K tokens. We conduct language modeling experiments on the arXiv dataset with the PPL evaluation and find that Qwen-7B can reach outstanding performance in the scenario of long context. Results are demonstrated below:
| Model | Sequence Length | ||||
|---|---|---|---|---|---|
| 1024 | 2048 | 4096 | 8192 | 16384 | |
| Qwen-7B | 4.23 | 3.78 | 39.35 | 469.81 | 2645.09 |
| + dynamic_ntk | 4.23 | 3.78 | 3.59 | 3.66 | 5.71 |
| + dynamic_ntk + logn | 4.23 | 3.78 | 3.58 | 3.56 | 4.62 |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.78 | 3.58 | 3.49 | 4.32 |
Reproduction
For your reproduction of the model performance on benchmark datasets, we provide scripts for you to reproduce the results. Check eval/EVALUATION.md for more information. Note that the reproduction may lead to slight differences from our reported results.
License Agreement
Researchers and developers are free to use the codes and model weights of both Qwen-7B and Qwen-7B-Chat. We also allow their commercial use. Check our license at LICENSE for more details.
Contact Us
If you are interested to leave a message to either our research team or product team, feel free to send an email to qianwen_opensource@alibabacloud.com.