32 KiB
![]()
Qwen-7B 🤖 | 🤗 | Qwen-7B-Chat 🤖 | 🤗 | Qwen-7B-Chat-Int4 🤗
WeChat | Discord | Demo | Report
{kind=link}
日本語ドキュメントメンテナー: Ikko Eltociear Ashimine & Junyang Lin
私たちは、Qwen-7B と Qwen-7B-Chat を 🤖 ModelScope と 🤗 Hugging Face の両方でオープンソース化しています(上部のロゴをクリックすると、コードとチェックポイントのあるリポジトリに移動します)。このレポには、Qwen-7B の簡単な紹介と、使い方の手引き、さらに詳しい情報を提供する技術メモ link が含まれています。
Qwen-7B は、アリババクラウドが提唱する大規模言語モデルシリーズ Qwen(略称:Tongyi Qianwen)の7Bパラメータ版になります。Qwen-7B は Transformer ベースの大規模言語モデルであり、ウェブテキスト、書籍、コードなどを含む大量のデータで事前学習されています。さらに、事前学習された Qwen-7B をベースに、アライメント技術で学習された大規模モデルベースの AI アシスタントである Qwen-7B-Chat をリリースします。Qwen-7B シリーズの特徴は以下の通りです:
- 高品質な事前トレーニングデータでトレーニング。Qwen-7B は 2.2 兆以上のトークンを含む大規模で高品質なデータセットに対して事前学習を行っっています。このデータセットには平文とコードが含まれ、一般的なドメインデータと専門的なドメインデータを含む幅広いドメインをカバーしている。
- 強いパフォーマンス。自然言語理解、数学、コーディングなどを評価する一連のベンチマークデータセットにおいて、同程度のモデルサイズのモデルと比較して、競合他社を凌駕しています。
- 言語サポートの向上。Qwen-7B のトークナイザは、15 万以上のトークンの語彙をベースにしており、他のトークナイザに比べて効率的です。多くの言語に対応しており、ユーザが特定の言語を理解するために Qwen-7B をさらにファインチューニングするのに役立ちます。
- 8K コンテキスト長をサポート。Qwen-7B と Qwen-7B-Chat はともに 8K のコンテキスト長をサポートしており、長いコンテキストでの入力を可能にしている。
- プラグインのサポート。Qwen-7B-Chat は、プラグイン関連のアライメントデータでトレーニングされているため、API、モデル、データベースなどのツールを使用することができ、エージェントとしてプレイすることができる。
以下のセクションには、参考になる情報が記載されています。特に、issue を立ち上げる前に FAQ セクションをお読みになることをお勧めします。
ニュースとアップデート
- 2023.9.12 Qwen-7Bモデルにおいて、フルパラメーター・ファインチューニング、LoRA、Q-LoRAを含むファインチューニングをサポートしました。
- 2023.8.21 Qwen-7B-Chat 用 Int4 量子化モデル Qwen-7B-Chat-Int4 をリリースしました。また、ベンチマーク評価においても大きな性能低下は見られませんでした。
- 2023.8.3 ModelScope と Hugging Face 上で Qwen-7B と Qwen-7B-Chat をリリースしました。また、トレーニングの詳細やモデルの性能など、モデルの詳細については技術メモを提供しています。
性能
Qwen-7B は、MMLU、C-Eval、GSM8K、HumanEval、WMT22、CMMLU など、自然言語理解、数学的問題解決、コーディングなどに関するモデルの能力を評価する一連のベンチマークデータセットにおいて、同程度のモデルサイズのベースラインモデルを凌駕しており、さらには 13B 程度のパラメータを持つより大規模なモデルをも凌駕しています。以下の結果をご覧ください。
| Model | MMLU | C-Eval | GSM8K | HumanEval | WMT22 (en-zh) | CMMLU |
|---|---|---|---|---|---|---|
| LLaMA-7B | 35.1 | - | 11.0 | 10.5 | 8.7 | - |
| LLaMA 2-7B | 45.3 | - | 14.6 | 12.8 | 17.9 | - |
| Baichuan-7B | 42.3 | 42.8 | 9.7 | 9.2 | 26.6 | 44.4 |
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 9.2 | - | 48.8 |
| InternLM-7B | 51.0 | 52.8 | 31.2 | 10.4 | 14.8 | - |
| Baichuan-13B | 51.6 | 53.6 | 26.6 | 12.8 | 30.0 | 55.8 |
| LLaMA-13B | 46.9 | 35.5 | 17.8 | 15.8 | 12.0 | - |
| LLaMA 2-13B | 54.8 | - | 28.7 | 18.3 | 24.2 | - |
| ChatGLM2-12B | 56.2 | 61.6 | 40.9 | - | - | - |
| Qwen-7B | 56.7 | 59.6 | 51.6 | 24.4 | 30.6 | 58.8 |
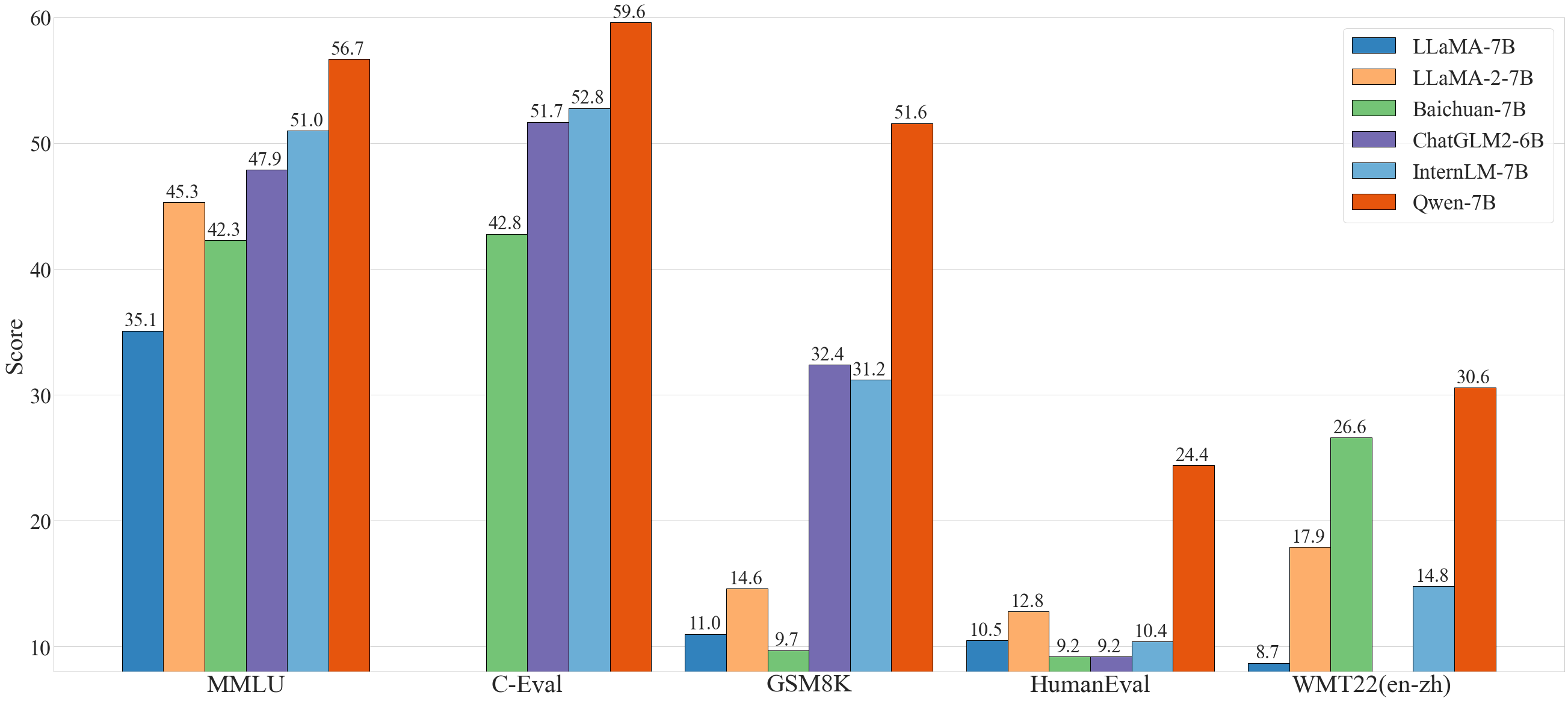
さらに、OpenCompass が実施した大規模言語モデルの第三者評価によると、Qwen-7B と Qwen-7B-Chat は 7B パラメータモデルのトップになります。この評価は、言語理解・生成、コーディング、数学、推論などの評価のための大量の公開ベンチマークで構成されています。
より詳細な実験結果(より多くのベンチマークデータセットでの詳細なモデル性能)や詳細については、こちらをクリックして技術メモを参照してください。
必要条件
- python 3.8 以上
- pytorch 1.12 以上、2.0 以上を推奨
- CUDA 11.4 以上を推奨(GPU ユーザー、フラッシュアテンションユーザー向けなど)
クイックスタート
以下では、Qwen-7B と 🤖 ModelScope と 🤗 Transformers の簡単な使用例を示します。
コードを実行する前に、環境のセットアップと必要なパッケージのインストールが済んでいることを確認してください。上記の要件を満たしていることを確認してから、依存するライブラリをインストールしてください。
pip install -r requirements.txt
お使いのデバイスが fp16 または bf16 をサポートしている場合、flash-attention をインストールすることで、より高い効率とメモリ使用量を抑えることができます。(flash-attention はオプションであり、インストールしなくてもプロジェクトは正常に実行できます)
git clone -b v1.0.8 https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 以下はオプションです。インストールに時間がかかる場合があります。
# pip install csrc/layer_norm
# pip install csrc/rotary
これで ModelScope か Transformers で始めることができます。
🤗 Transformers
Qwen-7B-Chat を推論に使用するには、以下のように数行のコードを入力するだけです。最新のコードを使用していることを確認してください。
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# 注: デフォルトの動作では、インジェクション攻撃防止機能がオフになっています。
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# bf16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# CPU のみ使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# オートモードを使用すると、デバイスに応じて自動的に精度が選択されます。
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータを指定
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 第一回対話ターン
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二回対話ターン
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话 第三回対話ターン
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
Qwen-7B の学習済みベースモデルの実行も簡単です。
Qwen-7B の実行
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
# bf16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, fp16=True).eval()
# CPU のみ使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="cpu", trust_remote_code=True).eval()
# オートモードを使用すると、デバイスに応じて自動的に精度が選択されます。
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータを指定
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
🤖 ModelScope
ModelScope は、MaaS(Model-as-a-Service) のためのオープンソースプラットフォームであり、AI 開発者に柔軟で費用対効果の高いモデルサービスを提供します。同様に、以下のように ModelScope でモデルを実行することができます:
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from modelscope import snapshot_download
model_id = 'QWen/qwen-7b-chat'
revision = 'v1.0.0'
model_dir = snapshot_download(model_id, revision)
pipe = pipeline(
task=Tasks.chat, model=model_dir, device_map='auto')
history = None
text = '浙江省の省都はどこですか?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
text = '何がそんなに面白いのか?'
results = pipe(text, history=history)
response, history = results['response'], results['history']
print(f'Response: {response}')
トークナイザー
tiktoken に基づくトークナイザーは、他のトークナイザー、例えばセンテンスピーストークナイザーとは異なります。特にファインチューニングの際には、特殊なトークンに注意を払う必要があります。トークナイザに関する詳細な情報や、ファインチューニングにおける使用方法については、ドキュメントを参照してください。
量子化
使用方法
注: AutoGPTQ に基づく新しい解決策を提供し、Qwen-7B-Chat 用の Int4 量子化モデルここをクリックをリリースしました。このモデルは、従来の解決策と比較して、ほぼ無損失のモデル効果を達成しつつ、メモリコストと推論速度の両方で性能が向上しています。
ここでは、量子化されたモデルを推論に使用する方法を説明する。始める前に、auto-gptqの要件を満たしていることを確認し(例:torch 2.0以上、transformers 4.32.0以上など)、必要なパッケージをインストールしてください:
pip install auto-gptq optimum
auto-gptq`のインストールに問題がある場合は、公式のrepoをチェックして、ホイールを見つけることをお勧めする。
そうすれば、量子化されたモデルを簡単にロードすることができ、いつもと同じように推論を実行することができる:
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B-Chat-Int4",
device_map="auto",
trust_remote_code=True
).eval()
response, history = model.chat(tokenizer, "Hi", history=None)
性能
ベンチマークにおける BF16 モデルと Int4 モデルの性能について説明します。その結果は以下に示します:
| Quantization | MMLU | CEval (val) | GSM8K | Humaneval |
|---|---|---|---|---|
| BF16 | 53.9 | 54.2 | 41.1 | 24.4 |
| Int4 | 52.6 | 52.9 | 38.1 | 23.8 |
推論スピード
BF16 の精度と Int4 の量子化レベルの下で、それぞれ 2048 個と 8192 個のトークンを生成する平均推論速度(tokens/s)を測定しました。
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
|---|---|---|
| BF16 | 30.34 | 29.32 |
| Int4 | 43.56 | 33.92 |
詳細には、プロファイリングの設定は、1 コンテクストトークンで 8192 個の新しいトークンを生成しています。プロファイリングは、PyTorch 2.0.1 と CUDA 11.4 を搭載したシングル A100-SXM4-80G GPU で実行されました。推論速度は生成された 8192 個のトークンの平均値となります。
GPU メモリ使用量
また、BF16またはInt4の量子化レベルで、それぞれ2048トークンをコンテキストとしてエンコードした場合(および単一のトークンを生成した場合)と、8192トークンを生成した場合(単一のトークンをコンテキストとして生成した場合)のGPUメモリ使用量のピーク値をプロファイリングしました。その結果を以下に示します。
| Quantization Level | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
|---|---|---|
| BF16 | 17.66GB | 22.58GB |
| Int4 | 8.21GB | 13.62GB |
上記のスピードとメモリーのプロファイリングは、このスクリプトを使用しています。
ファインチューニング
現在、公式のトレーニングスクリプト finetune.py を提供しています。さらに、finetune.pyのシェルスクリプトを提供し、finetune.pyを実行することで、finetune.pyを起動することができる。さらに、安心してファインチューニングを開始するためのシェルスクリプトも提供しています。このスクリプトは、DeepSpeed および FSDP を使用したトレーニングをサポートします。弊社が提供するシェル・スクリプトは DeepSpeed を使用するため、事前に DeepSpeed をインストールすることをお勧めします:
学習データを準備するには、すべてのサンプルをリストにまとめ、jsonファイルに保存する必要があります。各サンプルはidと会話リストで構成される辞書です。以下は1つのサンプルを含む単純なリストの例です:
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好",
},
{
"from": "assistant",
"value": "我是一个语言模型,我叫通义千问。"
}
]
}
]
データ準備の後、提供されているシェルスクリプトを使って微調整を実行することができる。データファイルのパス $DATA を忘れずに指定してください。
ファインチューニングのスクリプトを使用することで、以下のことが可能になる:
- フルパラメーター・ファインチューニング
- LoRA
- Q-LoRA
フルパラメータパラメータのファインチューニングを行うには、トレーニングプロセス全体ですべてのパラメータを更新する必要があります。トレーニングを開始するには、以下のスクリプトを実行します:
# 分散トレーニング。GPUメモリが不足するとトレーニングが破綻するため、シングルGPUのトレーニングスクリプトは提供していません。
sh finetune/finetune_ds.sh
シェルスクリプトでは、正しいモデル名またはパス、データパス、出力ディレクトリを指定することを忘れないでください。このスクリプトでは DeepSpeed ZeRO 3 を使用しています。変更したい場合は、引数 --deepspeed を削除するか、要件に基づいて DeepSpeed 設定 json ファイルを変更してください。さらに、このスクリプトは混合精度のトレーニングに対応しており、--bf16 True または --fp16 True を使用することができます。経験的に、あなたのマシンがbf16をサポートしている場合、私たちのプリトレーニングとアライメントを整合させるためにbf16を使用することをお勧めします。
同様に、LoRAを実行するには、以下のように別のスクリプトを使って実行する。始める前に、peftがインストールされていることを確認してください。また、モデル、データ、出力へのパスを指定する必要があります。学習済みモデルには絶対パスを使用することをお勧めします。なぜなら、LoRAはアダプタのみを保存し、アダプタ設定jsonファイルの絶対パスは、ロードする事前学習済みモデルを見つけるために使用されるからです。また、このスクリプトはbf16とfp16の両方をサポートしている。
# シングルGPUトレーニング
sh finetune/finetune_lora_single_gpu.sh
# 分散トレーニング
sh finetune/finetune_lora_ds.sh
LoRA (論文) は、フルパラメーターによるファインチューニングと比較して、adapterのパラメーターを更新するだけで、元の大きな言語モデル層は凍結されたままである。そのため、メモリコストが大幅に削減でき、計算コストも削減できる。しかし、それでもメモリ不足に悩む場合は、Q-LoRA(論文)を検討することができます。これは、量子化されたラージ言語モデルと、ページド・アテンションなどの他のテクニックを使用し、さらに少ないメモリコストで実行することができます。Q-LoRAを実行するには、以下のスクリプトを直接実行してください:
# シングルGPUトレーニング
sh finetune/finetune_qlora_single_gpu.sh
# 分散トレーニング
sh finetune/finetune_qlora_ds.sh
Q-LoRAについては、弊社が提供する量子化モデル、例えばQwen-7B-Chat-Int4をロードすることをお勧めします。ただし、フルパラメータ・ファインチューニングやLoRAとは異なり、Q-LoRAではfp16のみがサポートされる。
LoRAとQ-LoRAの学習は、フルパラメータによるファインチューニングとは異なり、アダプターパラメータのみを保存する。仮にQwen-7Bから学習を開始したとすると、以下のようにファインチューニングされたモデルを読み込んで推論を行うことができる:
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
path_to_adapter, # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
シェルスクリプトはtorchrunを使用してシングルGPUまたはマルチGPUトレーニングを実行します。そのため、分散トレーニングのための適切なハイパーパラメータをマシンに応じて指定する必要があります。
デモ
ウェブ UI
ウェブ UI デモを構築するためのコードを提供します(@wysaid に感謝)。これを始める前に、以下のパッケージがインストールされていることを確認してください:
pip install -r requirements_web_demo.txt
そして、以下のコマンドを実行し、生成されたリンクをクリックします:
python web_demo.py

CLI デモ
cli_demo.py に CLI のデモ例を用意しています。ユーザはプロンプトを入力することで Qwen-7B-Chat と対話することができ、モデルはストリーミングモードでモデルの出力を返します。以下のコマンドを実行する:
python cli_demo.py
API
OpenAI API をベースにローカルAPIをデプロイする方法を提供する(@hanpenggit に感謝)。始める前に、必要なパッケージをインストールしてください:
pip install fastapi uvicorn openai pydantic sse_starlette
それから、API をデプロイするコマンドを実行します:
python openai_api.py
チェックポイント名やパスには -c、CPU デプロイメントには --cpu-only など、引数を変更できます。API デプロイメントを起動する際に問題が発生した場合は、パッケージを最新バージョンに更新することで解決できる可能性があります。
API の使い方も簡単です。以下の例をご覧ください:
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
# ストリーミングレスポンスを有効化するリクエストを作成する
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
# ストリーミング出力形式でのストップワードの指定はまだサポートされておらず、開発中です。
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
# ストリーミングレスポンスを有効化しないリクエストを作成する
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=False,
stop=[] # 例えば、stop=["Observation:"] (ReAct プロンプトの場合)。
)
print(response.choices[0].message.content)

デプロイ
CPU 上でモデルを実行するのは簡単であり、以下のようにデバイスを指定する必要があります:
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
メモリ不足に悩まされ、複数の GPU にモデルをデプロイしたい場合は、utils.py で提供されているスクリプトを使うことができます:
from utils import load_model_on_gpus
model = load_model_on_gpus('Qwen/Qwen-7B-Chat', num_gpus=2)
7B チャットモデルの推論を 2GPU で実行できます。
ツールの使用
Qwen-7B-Chat は、API、データベース、モデルなど、ツールの利用に特化して最適化されており、ユーザは独自の Qwen-7B ベースの LangChain、エージェント、コードインタプリタを構築することができます。ツール利用能力を評価するための評価ベンチマークでは、Qwen-7B は安定した性能に達しています。
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
|---|---|---|---|
| GPT-4 | 95% | 0.90 | 15% |
| GPT-3.5 | 85% | 0.88 | 75% |
| Qwen-7B-Chat | 99% | 0.89 | 9.7% |
ReAct プロンプトの書き方や使い方については、ReAct の例を参照してください。ツールを使用することで、モデルがよりよいタスクを実行できるようになります。
さらに、エージェントとしての能力を示す実験結果を提供する。詳細は Hugging Face Agent を参照して下さい。Hugging Face が提供するランモードベンチマークでの性能は以下の通りです:
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
|---|---|---|---|
| GPT-4 | 100 | 100 | 97.41 |
| GPT-3.5 | 95.37 | 96.30 | 87.04 |
| StarCoder-15.5B | 87.04 | 87.96 | 68.89 |
| Qwen-7B-Chat | 90.74 | 92.59 | 74.07 |
長い文脈の理解
コンテキストの長さを拡張し、訓練シーケンスの長さのボトルネックを解消するために、NTK を考慮した補間、ウィンドウアテンション、LogN アテンションスケーリングなどの技術を導入し、コンテキストの長さを 8K トークン以上に拡張する。arXiv データセットを用いて PPL 評価による言語モデリング実験を行い、Qwen-7B が長いコンテキストのシナリオにおいて卓越した性能を達成できることを見出した。以下に結果を示します:
| Model | Sequence Length | ||||
|---|---|---|---|---|---|
| 1024 | 2048 | 4096 | 8192 | 16384 | |
| Qwen-7B | 4.23 | 3.78 | 39.35 | 469.81 | 2645.09 |
| + dynamic_ntk | 4.23 | 3.78 | 3.59 | 3.66 | 5.71 |
| + dynamic_ntk + logn | 4.23 | 3.78 | 3.58 | 3.56 | 4.62 |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.78 | 3.58 | 3.49 | 4.32 |
再現
ベンチマークデータセットでのモデル性能の再現のために、結果を再現するスクリプトを提供しています。詳しくは eval/EVALUATION.md を確認してください。なお、再現の結果、我々の報告結果と若干異なる場合があります。
FAQ
問題が発生した場合は、まずは FAQ や issue を参照し、新しい issue を立ち上げる前に解決策を探してください。
ライセンス契約
Qwen-7B と Qwen-7B-Chat のコードとモデルウェイトは、研究者や開発者が自由に使用することができます。また、商用利用も可能です。詳しくは LICENSE をご覧ください。商用利用を希望される方は、リクエストフォームに必要事項をご記入の上、お申し込みください。
お問い合わせ
研究チームまたは製品チームへのメッセージは、qianwen_opensource@alibabacloud.com までお気軽にお送りください。