![]()
🤗 Hugging Face | 🤖 ModelScope | 📑 Paper | 🖥️ Demo
WeChat (微信) | DingTalk (钉钉) | Discord

| Model | MMLU | C-Eval | GSM8K | MATH | HumanEval | MBPP | BBH | CMMLU |
|:-------------------|:--------:|:--------:|:--------:|:--------:|:---------:|:--------:|:--------:|:--------:|
| | 5-shot | 5-shot | 8-shot | 4-shot | 0-shot | 3-shot | 3-shot | 5-shot |
| LLaMA2-7B | 46.8 | 32.5 | 16.7 | 3.3 | 12.8 | 20.8 | 38.2 | 31.8 |
| LLaMA2-13B | 55.0 | 41.4 | 29.6 | 5.0 | 18.9 | 30.3 | 45.6 | 38.4 |
| LLaMA2-34B | 62.6 | - | 42.2 | 6.2 | 22.6 | 33.0 | 44.1 | - |
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 6.5 | - | - | 33.7 | - |
| InternLM-7B | 51.0 | 53.4 | 31.2 | 6.3 | 10.4 | 14.0 | 37.0 | 51.8 |
| InternLM-20B | 62.1 | 58.8 | 52.6 | 7.9 | 25.6 | 35.6 | 52.5 | 59.0 |
| Baichuan2-7B | 54.7 | 56.3 | 24.6 | 5.6 | 18.3 | 24.2 | 41.6 | 57.1 |
| Baichuan2-13B | 59.5 | 59.0 | 52.8 | 10.1 | 17.1 | 30.2 | 49.0 | 62.0 |
| Qwen-7B (original) | 56.7 | 59.6 | 51.6 | 10.4 | 24.4 | 31.2 | 40.6 | 58.8 |
| **Qwen-7B** | 58.2 | 63.5 | 51.7 | 11.6 | 29.9 | 31.6 | 45.0 | 62.2 |
| **Qwen-14B** | **66.3** | **72.1** | **61.3** | **24.8** | **32.3** | **40.8** | **53.4** | **71.0** |
For all compared models, we report the best scores between their official reported results and [OpenCompass](https://opencompass.org.cn/leaderboard-llm).
For more experimental results (detailed model performance on more benchmark datasets) and details, please refer to our technical report by clicking [here](https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf).
## Requirements
* python 3.8 and above
* pytorch 1.12 and above, 2.0 and above are recommended
* transformers 4.32 and above
* CUDA 11.4 and above are recommended (this is for GPU users, flash-attention users, etc.)
## Quickstart
Below, we provide simple examples to show how to use Qwen-Chat with 🤖 ModelScope and 🤗 Transformers.
Before running the code, make sure you have setup the environment and installed the required packages. Make sure you meet the above requirements, and then install the dependent libraries.
```bash
pip install -r requirements.txt
```
If your device supports fp16 or bf16, we recommend installing [flash-attention](https://github.com/Dao-AILab/flash-attention) (**we support flash attention 2 now.**) for higher efficiency and lower memory usage. (**flash-attention is optional and the project can run normally without installing it**)
```bash
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# Below are optional. Installing them might be slow.
# pip install csrc/layer_norm
# pip install csrc/rotary
```
Now you can start with ModelScope or Transformers.
#### 🤗 Transformers
To use Qwen-Chat for the inference, all you need to do is to input a few lines of codes as demonstrated below. Remember to pass in the correct model names or paths, such as "Qwen/Qwen-7B-Chat" and "Qwen/Qwen-14B-Chat". However, **please make sure that you are using the latest code.**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# Model names: "Qwen/Qwen-7B-Chat", "Qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B-Chat",
device_map="auto",
trust_remote_code=True
).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 2nd dialogue turn
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 3rd dialogue turn
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
```
Running Qwen pretrained base model is also simple.
In the event of a network issue while attempting to download model checkpoints and codes from HuggingFace, an alternative approach is to initially fetch the checkpoint from ModelScope and then load it from the local directory as outlined below:
```python
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# Downloading model checkpoint to a local dir model_dir
# model_dir = snapshot_download('qwen/Qwen-7B', revision='v1.1.4')
# model_dir = snapshot_download('qwen/Qwen-7B-Chat', revision='v1.1.4')
# model_dir = snapshot_download('qwen/Qwen-14B', revision='v1.0.4')
model_dir = snapshot_download('qwen/Qwen-14B-Chat', revision='v1.0.4')
# Loading local checkpoints
# trust_remote_code is still set as True since we still load codes from local dir instead of transformers
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
device_map="auto",
trust_remote_code=True
).eval()
```
#### 🤖 ModelScope
ModelScope is an opensource platform for Model-as-a-Service (MaaS), which provides flexible and cost-effective model service to AI developers. Similarly, you can run the models with ModelScope as shown below:
```python
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
# Model names: "qwen/Qwen-7B-Chat", "qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", revision='v1.0.5', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", revision='v1.0.5', device_map="auto", trust_remote_code=True, fp16=True).eval()
model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", revision='v1.0.5', trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history)
print(response)
response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history)
print(response)
```
Running Qwen
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# Model names: "Qwen/Qwen-7B", "Qwen/Qwen-14B"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B",
device_map="auto",
trust_remote_code=True
).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
```
## Quantization
### Usage
We provide a solution based on [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ), and release an Int4 quantized model for Qwen-7B-Chat [Click here](https://huggingface.co/Qwen/Qwen-7B-Chat-Int4) and Qwen-14B-Chat [Click here](https://huggingface.co/Qwen/Qwen-14B-Chat-Int4), which achieve nearly lossless model effects but improved performance on both memory costs and inference speed.
Here we demonstrate how to use our provided quantized models for inference. Before you start, make sure you meet the requirements of auto-gptq (e.g., torch 2.0 and above, transformers 4.32.0 and above, etc.) and install the required packages:
```bash
pip install auto-gptq optimum
```
If you meet problems installing `auto-gptq`, we advise you to check out the official [repo](https://github.com/PanQiWei/AutoGPTQ) to find a wheel.
Then you can load the quantized model easily and run inference as same as usual:
```python
# Model names: "Qwen/Qwen-7B-Chat-Int4", "Qwen/Qwen-14B-Chat-Int4"
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B-Chat-Int4",
device_map="auto",
trust_remote_code=True
).eval()
response, history = model.chat(tokenizer, "Hi", history=None)
```
### Performance
We illustrate the model performance of both BF16 and Int4 models on the benchmark, and we find that the quantized model does not suffer from significant performance degradation. Results are shown below:
| Quantization | MMLU | CEval (val) | GSM8K | Humaneval |
|----------------------|:----:|:-----------:|:-----:|:---------:|
| Qwen-7B-Chat (BF16) | 53.9 | 54.2 | 41.1 | 24.4 |
| Qwen-7B-Chat (Int4) | 52.6 | 52.9 | 38.1 | 23.8 |
| Qwen-14B-Chat (BF16) | 64.6 | 69.8 | 61.0 | 43.9 |
| Qwen-14B-Chat (Int4) | 63.3 | 69.0 | 59.8 | 45.7 |
### Inference Speed
We measured the average inference speed (tokens/s) of generating 2048 and 8192 tokens under BF16 precision and Int4 quantization, respectively.
| Quantization | Speed (2048 tokens) | Speed (8192 tokens) |
|----------------------|:-------------------:|:-------------------:|
| Qwen-7B-Chat (BF16) | 30.34 | 29.32 |
| Qwen-7B-Chat (Int4) | 43.56 | 33.92 |
| Qwen-14B-Chat (BF16) | 30.70 | 21.73 |
| Qwen-14B-Chat (Int4) | 37.11 | 26.11 |
In detail, the setting of profiling is generating 8192 new tokens with 1 context token. The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.4. The inference speed is averaged over the generated 8192 tokens.
### GPU Memory Usage
We also profile the peak GPU memory usage for encoding 2048 tokens as context (and generating single token) and generating 8192 tokens (with single token as context) under BF16 or Int4 quantization level, respectively. The results are shown below.
| Quantization | Peak Usage for Encoding 2048 Tokens | Peak Usage for Generating 8192 Tokens |
|----------------------|:-----------------------------------:|:-------------------------------------:|
| Qwen-7B-Chat (BF16) | 17.66GB | 22.58GB |
| Qwen-7B-Chat (Int4) | 8.21GB | 13.62GB |
| Qwen-14B-Chat (BF16) | 30.15GB | 38.94GB |
| Qwen-14B-Chat (Int4) | 13.00GB | 21.79GB |
The above speed and memory profiling are conducted using [this script](https://qianwen-res.oss-cn-beijing.aliyuncs.com/profile.py).
## Quantization of KV cache
Attention KV cache can be quantized and compressed for storage, to get a higher sample throughput.
### Usage
The parameters of 'use_cache_quantization' and 'use_cache_kernel' are provided to control kv-cache-quantization behavior
When use_cache_quantization=True and use_cache_kernel=True, kv-cache-quantization will be enabled.
The specific use method is as follows:
```python
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen-7B-Chat",
device_map="auto",
trust_remote_code=True,
use_cache_quantization=True,
use_cache_kernel=True,
use_flash_attn=False
)
```
Attention:
Currently, kv-cache-quantization and flash attn cannot be turned on at the same time.
If you enable kv cache quantization and use_flash_attn at the same time (use_flash_attn=True, use_cache_quantization=True, use_cache_kernel=True), use_flash_attn is disabled by default(use_flash_attn=false).
### Comparative Results
#### Results
We have verified that the use of the quantized int8-kvcache model does not suffer from significant performance degradation.
#### memory usage comparison
The profiling runs on a single A100-SXM4-80G GPU with PyTorch 2.0.1 and CUDA 11.4.
We use BF16 models, and generate 1024 tokens (seq-length=1024) by default, and oom indicates out of memory.
With kv-cache quantization turned on, we can run a larger batch size(bs).
| USE KVCache | bs=1 | bs=4 | bs=16 | bs=32 | bs=64 | bs=100 |
|-------------|:------:|:------:|:------:|:------:|:------:|:------:|
| no | 16.3GB | 24.1GB | 31.7GB | 48.7GB | oom | oom |
| yes | 15.5GB | 17.2GB | 22.3GB | 30.2GB | 48.2GB | 72.4GB |
With kv-cache quantization turned on, the model can save more memory when generate longer seq-length (sl, number of tokens generated) at infer.
| USE KVCache | sl=512 | sl=1024 | sl=2048 | sl=4096 | sl=8192 |
|-------------|:------:|:-------:|:-------:|:-------:|:-------:|
| no | 15.2GB | 16.3GB | 17.6GB | 19.5GB | 23.2GB |
| yes | 15GB | 15.5GB | 15.8GB | 16.6GB | 17.6GB |
### Difference of Storage in layer-past
The model which turn on the kv-cache quantization will convert the format of layer-past from float to int8, meanwhile the quantianted layer-past will also store quantiantion parameters of current value.
Specific steps are as follows:
1、Quantize key/value
```
qv,scale,zero_point=quantize_cache_v(v)
```
2、Store into layer_past
Following is the format of quantized layer_past:
```
layer_past=((q_key,key_scale,key_zero_point),
(q_value,value_scale,value_zero_point))
```
Bascial format of layer_past:
```
layer_past=(key,value)
```
If you want to use the attention KV which is quantized,
you can use the dequantization operation to convert the int8 key/value back to the float format as following:
```
v=dequantize_cache_torch(qv,scale,zero_point)
```
## Batch Inference
Qwen supports batch inference. With flash-attention enabled, using batch inference can bring a 40% speedup. The example code is shown below:
```
import torch
from tokenization_qwen import QWenTokenizer
from modeling_qwen import QWenLMHeadModel
from transformers import GenerationConfig
from qwen_generation_utils import make_context, decode_tokens, get_stop_words_ids
tokenizer = QWenTokenizer.from_pretrained('./', pad_token='<|extra_0|>', eos_token='<|endoftext|>', padding_side='left')
model = QWenLMHeadModel.from_pretrained('./', device_map="auto").eval()
model.generation_config = GenerationConfig.from_pretrained('./')
stop_words_ids = get_stop_words_ids(model.generation_config.chat_format, tokenizer)
all_raw_text = ["我想听你说爱我。", "今天我想吃点啥,甜甜的,推荐下", "我马上迟到了,怎么做才能不迟到"]
batch_raw_text = []
for q in all_raw_text:
raw_text, _ = make_context(
tokenizer,
q,
system="You are a helpful assistant.",
max_window_size=model.generation_config.max_window_size,
chat_format=model.generation_config.chat_format,
)
batch_raw_text.append(raw_text)
batch_input_ids = tokenizer(batch_raw_text, padding='longest')
batch_input_ids = torch.LongTensor(batch_input_ids['input_ids']).to(model.device)
batch_out_ids = model.generate(
batch_input_ids,
stop_words_ids=stop_words_ids,
return_dict_in_generate=False,
generation_config=model.generation_config
)
padding_lens = [batch_input_ids[i].eq(tokenizer.pad_token_id).sum().item() for i in range(batch_input_ids.size(0))]
batch_response = [
decode_tokens(
batch_out_ids[i][padding_lens[i]:],
tokenizer,
raw_text_len=len(batch_raw_text[i]),
context_length=batch_input_ids[i].size(0),
chat_format="chatml",
verbose=False,
errors='replace'
) for i in range(len(all_raw_text))
]
print(batch_response)
response, _ = model.chat(tokenizer, "我想听你说爱我。", history=None)
print(response)
response, _ = model.chat(tokenizer, "今天我想吃点啥,甜甜的,推荐下", history=None)
print(response)
response, _ = model.chat(tokenizer, "我马上迟到了,怎么做才能不迟到", history=None)
print(response)
```
## Finetuning
### Usage
Now we provide the official training script, `finetune.py`, for users to finetune the pretrained model for downstream applications in a simple fashion. Additionally, we provide shell scripts to launch finetuning with no worries. This script supports the training with [DeepSpeed](https://github.com/microsoft/DeepSpeed) and [FSDP](https://engineering.fb.com/2021/07/15/open-source/fsdp/). The shell scripts that we provide use DeepSpeed (Note: this may have conflicts with the latest version of pydantic) and Peft. You can install them by:
```bash
pip install peft deepspeed
```
To prepare your training data, you need to put all the samples into a list and save it to a json file. Each sample is a dictionary consisting of an id and a list for conversation. Below is a simple example list with 1 sample:
```json
[
{
"id": "identity_0",
"conversations": [
{
"from": "user",
"value": "你好"
},
{
"from": "assistant",
"value": "我是一个语言模型,我叫通义千问。"
}
]
}
]
```
After data preparation, you can use the provided shell scripts to run finetuning. Remember to specify the path to the data file, `$DATA`.
The finetuning scripts allow you to perform:
- Full-parameter finetuning
- LoRA
- Q-LoRA
Full-parameter parameter finetuning requires updating all parameters in the whole training process. To launch your training, run the following script:
```bash
# Distributed training. We do not provide single-GPU training script as the insufficient GPU memory will break down the training.
sh finetune/finetune_ds.sh
```
Remember to specify the correct model name or path, the data path, as well as the output directory in the shell scripts. Another thing to notice is that we use DeepSpeed ZeRO 3 in this script. If you want to make changes, just remove the argument `--deepspeed` or make changes in the DeepSpeed configuration json file based on your requirements. Additionally, this script supports mixed-precision training, and thus you can use `--bf16 True` or `--fp16 True`. Empirically we advise you to use bf16 to make your training consistent with our pretraining and alignment if your machine supports bf16, and thus we use it by default.
Similarly, to run LoRA, use another script to run as shown below. Before you start, make sure that you have installed `peft`. Also, you need to specify your paths to your model, data, and output. We advise you to use absolute path for your pretrained model. This is because LoRA only saves the adapter and the absolute path in the adapter configuration json file is used for finding out the pretrained model to load. Also, this script support both bf16 and fp16.
```bash
# Single GPU training
sh finetune/finetune_lora_single_gpu.sh
# Distributed training
sh finetune/finetune_lora_ds.sh
```
In comparison with full-parameter finetuning, LoRA ([paper](https://arxiv.org/abs/2106.09685)) only updates the parameters of adapter layers but keeps the original large language model layers frozen. This allows much fewer memory costs and thus fewer computation costs.
Note that if you use LoRA to finetune the base language model, e.g., Qwen-7B, instead of chat models, e.g., Qwen-7B-Chat, the script automatically switches the embedding and output layer as trainable parameters. This is because the base language model has no knowledge of special tokens brought by ChatML format. Thus these layers should be updated for the model to understand and predict the tokens. Or in another word, if your training brings in special tokens in LoRA, you should set the layers to trainable parameters by setting `modules_to_save` inside the code. Additionally, we find that there is a significant gap between the memory footprint of LoRA with and without these trainable parameters. Therefore, if you have trouble with memory, we advise you to LoRA finetune the chat models. Check the profile below for more information.
If you still suffer from insufficient memory, you can consider Q-LoRA ([paper](https://arxiv.org/abs/2305.14314)), which uses the quantized large language model and other techniques such as paged attention to allow even fewer memory costs.
Note: To run single-GPU Q-LoRA training, you may need to install `mpi4py` through `pip` or `conda`.
To run Q-LoRA, directly run the following script:
```bash
# Single GPU training
sh finetune/finetune_qlora_single_gpu.sh
# Distributed training
sh finetune/finetune_qlora_ds.sh
```
For Q-LoRA, we advise you to load our provided quantized model, e.g., Qwen-7B-Chat-Int4. You **SHOULD NOT** use the bf16 models. Different from full-parameter finetuning and LoRA, only fp16 is supported for Q-LoRA. Besides, for Q-LoRA, the troubles with the special tokens in LoRA still exist. However, as we only provide the Int4 models for chat models, which means the language model has learned the special tokens of ChatML format, you have no worry about the layers. Note that the layers of the Int4 model should not be trainable, and thus if you introduce special tokens in your training, Q-LoRA might not work.
Different from full-parameter finetuning, the training of both LoRA and Q-LoRA only saves the adapter parameters. Suppose your training starts from Qwen-7B, you can load the finetuned model for inference as shown below:
```python
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
path_to_adapter, # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
```
If you want to merge the adapters and save the finetuned model as a standalone model (you can only do this with LoRA, and you CANNOT merge the parameters from Q-LoRA), you can run the following codes:
```python
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
path_to_adapter, # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
merged_model = model.merge_and_unload()
# max_shard_size and safe serialization are not necessary.
# They respectively work for sharding checkpoint and save the model to safetensors
merged_model.save_pretrained(new_model_directory, max_shard_size="2048MB", safe_serialization=True)
```
Note: For multi-GPU training, you need to specify the proper hyperparameters for distributed training based on your machine. Besides, we advise you to specify your maximum sequence length with the argument `--model_max_length`, based on your consideration of data, memory footprint, and training speed.
### Profiling of Memory and Speed
We profile the GPU memory and training speed of both LoRA (LoRA (emb) refers to training the embedding and output layer, while LoRA has no trainable embedding and output layer) and Q-LoRA in the setup of single-GPU training. In this test, we experiment on a single A100-SXM4-80G GPU, and we use CUDA 11.8 and Pytorch 2.0. Flash attention 2 is applied. We uniformly use a batch size of 1 and gradient accumulation of 8. We profile the memory (GB) and speed (s/iter) of inputs of different lengths, namely 256, 512, 1024, 2048, 4096, and 8192. We also report the statistics of full-parameter finetuning with Qwen-7B on 2 A100 GPUs. We only report the statistics of 256, 512, and 1024 tokens due to the limitation of GPU memory. The statistics are listed below:
| Model Size | Method | Sequence Length | |||||
|---|---|---|---|---|---|---|---|
| 256 | 512 | 1024 | 2048 | 4096 | 8192 | ||
| 7B | LoRA | 20.1G / 1.2s/it | 20.4G / 1.5s/it | 21.5G / 2.8s/it | 23.8G / 5.2s/it | 29.7G / 10.1s/it | 36.6G / 21.3s/it |
| LoRA (emb) | 33.7G / 1.4s/it | 34.1G / 1.6s/it | 35.2G / 2.9s/it | 35.1G / 5.3s/it | 39.2G / 10.3s/it | 48.5G / 21.7s/it | |
| Q-LoRA | 11.5G / 3.0s/it | 11.5G / 3.0s/it | 12.3G / 3.5s/it | 13.9G / 7.0s/it | 16.9G / 11.6s/it | 23.5G / 22.3s/it | |
| Full-parameter | 139.2G / 4.0s/it | 148.0G / 4.0s/it | 162.0G / 4.5s/it | - | - | - | |
| 14B | LoRA | 34.6G / 1.6s/it | 35.1G / 2.4s/it | 35.3G / 4.4s/it | 37.4G / 8.4s/it | 42.5G / 17.0s/it | 55.2G / 36.0s/it |
| LoRA (emb) | 51.2 / 1.7s/it | 51.1G / 2.6s/it | 51.5G / 4.6s/it | 54.1G / 8.6s/it | 56.8G / 17.2s/it | 67.7G / 36.3s/it | |
| Q-LoRA | 18.7G / 5.3s/it | 18.4G / 6.3s/it | 18.9G / 8.2s/it | 19.9G / 11.8s/it | 23.0G / 20.1s/it | 27.9G / 38.3s/it | |

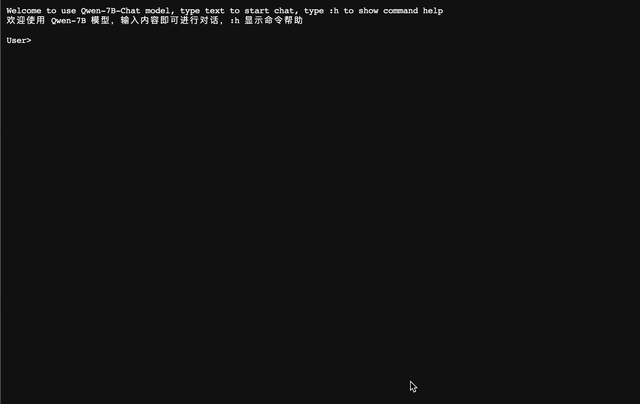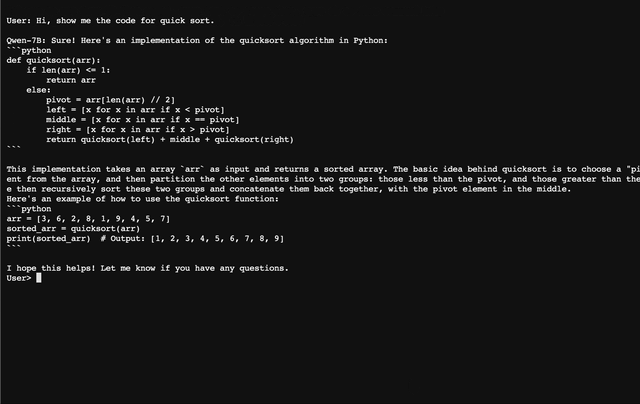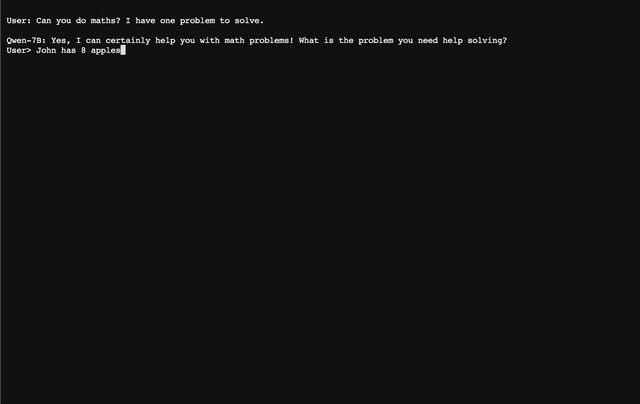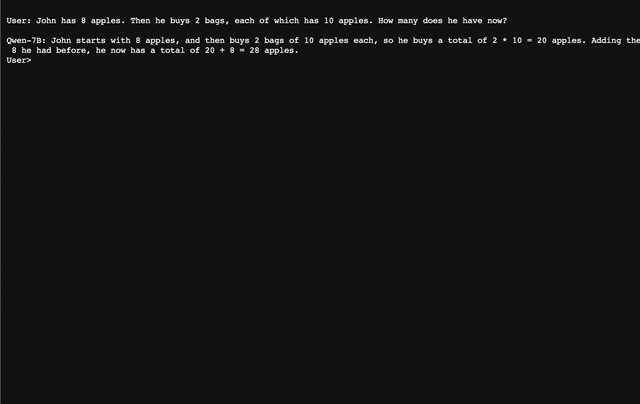
### CLI Demo We provide a CLI demo example in `cli_demo.py`, which supports streaming output for the generation. Users can interact with Qwen-7B-Chat by inputting prompts, and the model returns model outputs in the streaming mode. Run the command below: ```bash python cli_demo.py ```
## API
We provide methods to deploy local API based on OpenAI API (thanks to @hanpenggit). Before you start, install the required packages:
```bash
pip install fastapi uvicorn openai "pydantic>=2.3.0" sse_starlette
```
Then run the command to deploy your API:
```bash
python openai_api.py
```
You can change your arguments, e.g., `-c` for checkpoint name or path, `--cpu-only` for CPU deployment, etc. If you meet problems launching your API deployment, updating the packages to the latest version can probably solve them.
Using the API is also simple. See the example below:
```python
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
# create a request activating streaming response
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
# Specifying stop words in streaming output format is not yet supported and is under development.
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
# create a request not activating streaming response
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=False,
stop=[] # You can add custom stop words here, e.g., stop=["Observation:"] for ReAct prompting.
)
print(response.choices[0].message.content)
```

Function calling is also supported (but only when `stream=False` for the moment). See the [example usage](examples/function_call_examples.py) here.
## Deployment
### CPU
To deploy our models on CPU, we strongly advise you to use [qwen.cpp](https://github.com/QwenLM/qwen.cpp), which is a pure C++ implementation of Qwen and tiktoken. Check the repo for more details!
Also, it is also simple to directly run the model on CPU, which requires your specification of device:
```python
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
```
However, it is likely that you suffer from extremely low inference efficiency.
### Multiple GPUs
If you suffer from lack of GPU memory and you would like to run the model on more than 1 GPU, you can directly use the default loading method, which is now supported by Transformers. The previous method based on `utils.py` is deprecated.
## Tool Usage
Qwen-Chat has been optimized for tool usage and function calling capabilities. Users can develop agents, LangChain applications, and even agument Qwen with a Python Code Interpreter.
We provide documentation on how to implement tool calls based on the principle of ReAct Prompting, please refer to [the ReAct example](examples/react_prompt.md). Based on this principle, we provide support for function calling in [openai_api.py](openai_api.py).
We have tested the model's tool calling capabilities on our open-source Chinese evaluation benchmark and found that Qwen-Chat consistently performs well:
| Chinese Tool-Use Benchmark | |||
|---|---|---|---|
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
| GPT-4 | 95% | 0.90 | 15.0% |
| GPT-3.5 | 85% | 0.88 | 75.0% |
| Qwen-7B-Chat | 98% | 0.91 | 7.3% |
| Qwen-14B-Chat | 98% | 0.93 | 2.4% |
| Executable Rate of Generated Code (%) | |||
|---|---|---|---|
| Model | Math↑ | Visualization↑ | General↑ |
| GPT-4 | 91.9 | 85.9 | 82.8 |
| GPT-3.5 | 89.2 | 65.0 | 74.1 |
| LLaMA2-7B-Chat | 41.9 | 33.1 | 24.1 |
| LLaMA2-13B-Chat | 50.0 | 40.5 | 48.3 |
| CodeLLaMA-7B-Instruct | 85.1 | 54.0 | 70.7 |
| CodeLLaMA-13B-Instruct | 93.2 | 55.8 | 74.1 |
| InternLM-7B-Chat-v1.1 | 78.4 | 44.2 | 62.1 |
| InternLM-20B-Chat | 70.3 | 44.2 | 65.5 |
| Qwen-7B-Chat | 82.4 | 64.4 | 67.2 |
| Qwen-14B-Chat | 89.2 | 84.1 | 65.5 |
| Accuracy of Code Execution Results (%) | |||
|---|---|---|---|
| Model | Math↑ | Visualization-Hard↑ | Visualization-Easy↑ |
| GPT-4 | 82.8 | 66.7 | 60.8 |
| GPT-3.5 | 47.3 | 33.3 | 55.7 |
| LLaMA2-7B-Chat | 3.9 | 14.3 | 39.2 |
| LLaMA2-13B-Chat | 8.3 | 8.3 | 40.5 |
| CodeLLaMA-7B-Instruct | 14.3 | 26.2 | 60.8 |
| CodeLLaMA-13B-Instruct | 28.2 | 27.4 | 62.0 |
| InternLM-7B-Chat-v1.1 | 28.5 | 4.8 | 40.5 |
| InternLM-20B-Chat | 34.6 | 21.4 | 45.6 |
| Qwen-7B-Chat | 41.9 | 40.5 | 54.4 |
| Qwen-14B-Chat | 58.4 | 53.6 | 59.5 |

In addition, we also provide experimental results demonstrating that our model is capable of acting as a HuggingFace Agent. For more information, please refer to the [example documentation](examples/transformers_agent.md). The model's performance on the evaluation dataset provided by Hugging Face is as follows:
| HuggingFace Agent Benchmark- Run Mode | |||
|---|---|---|---|
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
| GPT-4 | 100 | 100 | 97.4 |
| GPT-3.5 | 95.4 | 96.3 | 87.0 |
| StarCoder-Base-15B | 86.1 | 87.0 | 68.9 |
| StarCoder-15B | 87.0 | 88.0 | 68.9 |
| Qwen-7B-Chat | 87.0 | 87.0 | 71.5 |
| Qwen-14B-Chat | 93.5 | 94.4 | 87.0 |
| HuggingFace Agent Benchmark - Chat Mode | |||
|---|---|---|---|
| Model | Tool Selection↑ | Tool Used↑ | Code↑ |
| GPT-4 | 97.9 | 97.9 | 98.5 |
| GPT-3.5 | 97.3 | 96.8 | 89.6 |
| StarCoder-Base-15B | 97.9 | 97.9 | 91.1 |
| StarCoder-15B | 97.9 | 97.9 | 89.6 |
| Qwen-7B-Chat | 94.7 | 94.7 | 85.1 |
| Qwen-14B-Chat | 97.9 | 97.9 | 95.5 |
| Model | Sequence Length | |||||
|---|---|---|---|---|---|---|
| 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | |
| Qwen-7B (original) | 4.23 | 3.78 | 39.35 | 469.81 | 2645.09 | - |
| + dynamic_ntk | 4.23 | 3.78 | 3.59 | 3.66 | 5.71 | - |
| + dynamic_ntk + logn | 4.23 | 3.78 | 3.58 | 3.56 | 4.62 | - |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.78 | 3.58 | 3.49 | 4.32 | - |
| Qwen-7B | 4.23 | 3.81 | 3.52 | 3.31 | 7.27 | 181.49 |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.81 | 3.52 | 3.33 | 3.22 | 3.17 |
| Qwen-14B | - | 3.46 | 22.79 | 334.65 | 3168.35 | - |
| + dynamic_ntk + logn + window_attn | - | 3.46 | 3.29 | 3.18 | 3.42 | - |
{kind=link}