中文 | English | 日本語 | Français | Español
![]()
🤗 Hugging Face | 🤖 ModelScope | 📑 Paper | 🖥️ Demo
WeChat (微信) | Discord | API

| Model | MMLU | C-Eval | GSM8K | MATH | HumanEval | MBPP | BBH | CMMLU |
|:------------------|:--------:|:--------:|:--------:|:--------:|:---------:|:--------:|:--------:|:--------:|
| | 5-shot | 5-shot | 8-shot | 4-shot | 0-shot | 3-shot | 3-shot | 5-shot |
| LLaMA2-7B | 46.8 | 32.5 | 16.7 | 3.3 | 12.8 | 20.8 | 38.2 | 31.8 |
| LLaMA2-13B | 55.0 | 41.4 | 29.6 | 5.0 | 18.9 | 30.3 | 45.6 | 38.4 |
| LLaMA2-34B | 62.6 | - | 42.2 | 6.2 | 22.6 | 33.0 | 44.1 | - |
| ChatGLM2-6B | 47.9 | 51.7 | 32.4 | 6.5 | - | - | 33.7 | - |
| InternLM-7B | 51.0 | 53.4 | 31.2 | 6.3 | 10.4 | 14.0 | 37.0 | 51.8 |
| InternLM-20B | 62.1 | 58.8 | 52.6 | 7.9 | 25.6 | 35.6 | 52.5 | 59.0 |
| Baichuan2-7B | 54.7 | 56.3 | 24.6 | 5.6 | 18.3 | 24.2 | 41.6 | 57.1 |
| Baichuan2-13B | 59.5 | 59.0 | 52.8 | 10.1 | 17.1 | 30.2 | 49.0 | 62.0 |
| Yi-34B | 76.3 | 81.8 | 67.9 | 15.9 | 26.2 | 38.2 | 66.4 | 82.6 |
| XVERSE-65B | 70.8 | 68.6 | 60.3 | - | 26.3 | - | - | - |
| **Qwen-1.8B** | 45.3 | 56.1 | 32.3 | 2.3 | 15.2 | 14.2 | 22.3 | 52.1 |
| **Qwen-7B** | 58.2 | 63.5 | 51.7 | 11.6 | 29.9 | 31.6 | 45.0 | 62.2 |
| **Qwen-14B** | 66.3 | 72.1 | 61.3 | 24.8 | 32.3 | 40.8 | 53.4 | 71.0 |
| **Qwen-72B** | **77.4** | **83.3** | **78.9** | **35.2** | **35.4** | **52.2** | **67.7** | **83.6** |
比較されたすべてのモデルについて、公式に報告された結果と[OpenCompass](https://opencompass.org.cn/leaderboard-llm) の間の最高スコアを報告します。
より詳細な実験結果(より多くのベンチマークデータセットでの詳細なモデル性能)や詳細については、[こちら](TODO)をクリックして技術メモを参照してください。
## 必要条件
* python 3.8 以上
* pytorch 1.12 以上、2.0 以上を推奨
* transformers 4.32 以上
* CUDA 11.4 以上を推奨(GPU ユーザー、フラッシュアテンションユーザー向けなど)
## クイックスタート
以下では、Qwen-Chat と 🤖 ModelScope と 🤗 Transformers の簡単な使用例を示します。
詳しくはセクション["ビルド済みDockerイメージの使用"](#-docker)を参照してください。
Dockerを使用しない場合は、環境のセットアップと必要なパッケージのインストールが済んでいることを確認してください。上記の要件を満たしていることを確認してから、依存するライブラリをインストールしてください。
```bash
pip install -r requirements.txt
```
お使いのデバイスが fp16 または bf16 をサポートしている場合、[flash-attention](https://github.com/Dao-AILab/flash-attention) (flash attention 2に対応しました)をインストールすることで、より高い効率とメモリ使用量を抑えることができます。(**flash-attention はオプションであり、インストールしなくてもプロジェクトは正常に実行できます**)
```bash
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 以下はオプションです。インストールに時間がかかる場合があります。
# pip install csrc/layer_norm
# flash-attn のバージョンが 2.1.1 以降の場合、以下は必要ありません。
# pip install csrc/rotary
```
これで ModelScope か Transformers で始めることができます。
### 🤗 Transformers
Qwen-Chat を推論に使用するには、以下のように数行のコードを入力するだけです。Qwen/Qwen-7B-Chat "や "Qwen/Qwen-14B-Chat "のように、正しいモデル名やパスを渡すことを忘れないでください。**最新のコードを使用していることを確認してください。**
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# Model names:"Qwen/Qwen-7B-Chat"、"Qwen/Qwen-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# bf16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# CPU のみ使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval()
# オートモードを使用すると、デバイスに応じて自動的に精度が選択されます。
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータを指定。ただし、4.32.0 以上のトTransformerを使用している場合は、これを行う必要はありません。
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
# 第一回対話ターン
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二回対話ターン
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话 第三回対話ターン
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
```
Qwen の学習済みベースモデルの実行も簡単です。
Qwen の実行
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# Model names:"Qwen/Qwen-7B"、"Qwen/Qwen-14B"
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True)
# bf16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, bf16=True).eval()
# fp16 を使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True, fp16=True).eval()
# CPU のみ使用
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="cpu", trust_remote_code=True).eval()
# オートモードを使用すると、デバイスに応じて自動的に精度が選択されます。
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B", device_map="auto", trust_remote_code=True).eval()
# 生成のためのハイパーパラメータを指定。ただし、4.32.0 以上のトTransformerを使用している場合は、これを行う必要はありません。
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True)
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
```
HuggingFaceからモデルのチェックポイントとコードをダウンロードする際にネットワークの問題が発生した場合、ModelScopeからチェックポイントをダウンロードする方法はこちらでございます。
```python from modelscope import snapshot_download from transformers import AutoModelForCausalLM, AutoTokenizer # Downloading model checkpoint to a local dir model_dir # model_dir = snapshot_download('qwen/Qwen-7B') # model_dir = snapshot_download('qwen/Qwen-7B-Chat') # model_dir = snapshot_download('qwen/Qwen-14B') model_dir = snapshot_download('qwen/Qwen-14B-Chat') # Loading local checkpoints # trust_remote_code is still set as True since we still load codes from local dir instead of transformers tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( model_dir, device_map="auto", trust_remote_code=True ).eval() ``` ### 🤖 ModelScope ModelScope は、MaaS(Model-as-a-Service) のためのオープンソースプラットフォームであり、AI 開発者に柔軟で費用対効果の高いモデルサービスを提供します。同様に、以下のように ModelScope でモデルを実行することができます: ```python from modelscope import AutoModelForCausalLM, AutoTokenizer from modelscope import GenerationConfig # Model names:"Qwen/Qwen-7B-Chat"、"Qwen/Qwen-14B-Chat" tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-7B-Chat", trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-7B-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval() model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-7B-Chat", trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参 response, history = model.chat(tokenizer, "你好", history=None) print(response) response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history) print(response) response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history) print(response) ``` ### バッチ推論 Qwenはバッチ推論をサポートしている。フラッシュ・アテンションを有効にした場合、バッチ推論を使用することで40%のスピードアップが期待できる。以下にコード例を示す: ```python import torch from transformers import AutoModelForCausalLM, AutoTokenizer from transformers import GenerationConfig from qwen_generation_utils import make_context, decode_tokens, get_stop_words_ids tokenizer = AutoTokenizer.from_pretrained( './', pad_token='<|extra_0|>', eos_token='<|endoftext|>', padding_side='left', trust_remote_code=True ) model = AutoModelForCausalLM.from_pretrained( './', pad_token_id=tokenizer.pad_token_id, device_map="auto", trust_remote_code=True ).eval() model.generation_config = GenerationConfig.from_pretrained('./', pad_token_id=tokenizer.pad_token_id) all_raw_text = ["我想听你说爱我。", "今天我想吃点啥,甜甜的,推荐下", "我马上迟到了,怎么做才能不迟到"] batch_raw_text = [] for q in all_raw_text: raw_text, _ = make_context( tokenizer, q, system="You are a helpful assistant.", max_window_size=model.generation_config.max_window_size, chat_format=model.generation_config.chat_format, ) batch_raw_text.append(raw_text) batch_input_ids = tokenizer(batch_raw_text, padding='longest') batch_input_ids = torch.LongTensor(batch_input_ids['input_ids']).to(model.device) batch_out_ids = model.generate( batch_input_ids, return_dict_in_generate=False, generation_config=model.generation_config ) padding_lens = [batch_input_ids[i].eq(tokenizer.pad_token_id).sum().item() for i in range(batch_input_ids.size(0))] batch_response = [ decode_tokens( batch_out_ids[i][padding_lens[i]:], tokenizer, raw_text_len=len(batch_raw_text[i]), context_length=(batch_input_ids[i].size(0)-padding_lens[i]), chat_format="chatml", verbose=False, errors='replace' ) for i in range(len(all_raw_text)) ] print(batch_response) response, _ = model.chat(tokenizer, "我想听你说爱我。", history=None) print(response) response, _ = model.chat(tokenizer, "今天我想吃点啥,甜甜的,推荐下", history=None) print(response) response, _ = model.chat(tokenizer, "我马上迟到了,怎么做才能不迟到", history=None) print(response) ``` ### CPU Qwenとtiktokenの純粋なC++実装である [qwen.cpp](https://github.com/QwenLM/qwen.cpp) を使用することを強くお勧めします。詳細はレポを確認してください! また、CPU上でモデルを直接実行することも簡単ですが、その場合はデバイスの指定が必要です: ```python model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B-Chat", device_map="cpu", trust_remote_code=True).eval() ``` ただし、推論効率が極端に低下する可能性があります。 ### 複数のGPU GPUメモリ不足に悩まされ、1つ以上のGPUでモデルを実行したい場合、Transformersでサポートされるようになったデフォルトのロード方法を直接使うことができます。以前の `utils.py` に基づく方法は非推奨です。 しかし、この方法は簡単ですが、ネイティブ・パイプライン並列の効率は低いです。FastChatでvLLMを使用することをお勧めします。 ### DashScope APIを通じてQwenを利用する最も簡単な方法は、Alibaba Cloudを通じたDashScope APIサービスです。その使い方を紹介します。さらに、OpenAIスタイルのAPIをご自身のサーバーにデプロイするためのスクリプトも提供しています。 DashScopeはAlibaba Cloudが提供する大規模言語モデルAPIサービスで、今回Qwenに対応した。DashScopeの背後にあるモデルは、詳細が提供されていない一時的な社内バージョンであることに注意してください。サービスには `qwen-turbo` と `qwen-plus` があり、前者はより高速に動作し、後者はより優れたパフォーマンスを実現している。詳細はドキュメント [こちら](https://dashscope.aliyun.com) を参照。 公式サイト [link](https://help.aliyun.com/zh/dashscope/developer-reference/activate-dashscope-and-create-an-api-key?spm=a2c4g.11186623.0.0.6c2774fahtfXdn) で DashScope アカウントを作成し、API キー (AK) を取得してください。AK は環境変数で設定することをお勧めします: ```bash export DASHSCOPE_API_KEY="YOUR_DASHSCOPE_API_KEY" ``` その後、パッケージをインストールし、ドキュメントは [こちら](https://help.aliyun.com/zh/dashscope/developer-reference/install-dashscope-sdk) をクリックしてください。Python をお使いの場合は、pip で DashScope をインストールできます: ```bash pip install dashscope ``` JAVA SDKを使用する場合は、この方法でインストールできます: ```xml| Model Size | Quantization | Speed (Tokens/s) | GPU Memory Usage |
| 1.8B | BF16 | 54.09 | 4.23GB |
| Int8 | 55.56 | 3.48GB | |
| Int4 | 71.07 | 2.91GB | |
| 7B | BF16 | 40.93 | 16.99GB |
| Int8 | 37.47 | 11.20GB | |
| Int4 | 50.09 | 8.21GB | |
| 14B | BF16 | 32.22 | 30.15GB |
| Int8 | 29.28 | 18.81GB | |
| Int4 | 38.72 | 13.01GB | |
| 72B | BF16 | 8.48 | 144.69GB (2xA100) |
| Int8 | 9.05 | 81.27GB (2xA100) | |
| Int4 | 11.32 | 48.86GB | |
| 72B + vLLM | BF16 | 17.60 | 2xA100 |
| Model Size | Method | Sequence Length | |||||
|---|---|---|---|---|---|---|---|
| 256 | 512 | 1024 | 2048 | 4096 | 8192 | ||
| 1.8B | LoRA | 6.7G / 1.0s/it | 7.4G / 1.0s/it | 8.4G / 1.1s/it | 11.0G / 1.7s/it | 16.2G / 3.3s/it | 21.8G / 6.8s/it |
| LoRA (emb) | 13.7G / 1.0s/it | 14.0G / 1.0s/it | 14.0G / 1.1s/it | 15.1G / 1.8s/it | 19.7G / 3.4s/it | 27.7G / 7.0s/it | |
| Q-LoRA | 5.8G / 1.4s/it | 6.0G / 1.4s/it | 6.6G / 1.4s/it | 7.8G / 2.0s/it | 10.2G / 3.4s/it | 15.8G / 6.5s/it | |
| Full-parameter | 43.5G / 2.1s/it | 43.5G / 2.2s/it | 43.5G / 2.2s/it | 43.5G / 2.3s/it | 47.1G / 2.8s/it | 48.3G / 5.6s/it | |
| 7B | LoRA | 20.1G / 1.2s/it | 20.4G / 1.5s/it | 21.5G / 2.8s/it | 23.8G / 5.2s/it | 29.7G / 10.1s/it | 36.6G / 21.3s/it |
| LoRA (emb) | 33.7G / 1.4s/it | 34.1G / 1.6s/it | 35.2G / 2.9s/it | 35.1G / 5.3s/it | 39.2G / 10.3s/it | 48.5G / 21.7s/it | |
| Q-LoRA | 11.5G / 3.0s/it | 11.5G / 3.0s/it | 12.3G / 3.5s/it | 13.9G / 7.0s/it | 16.9G / 11.6s/it | 23.5G / 22.3s/it | |
| Full-parameter | 139.2G / 4.0s/it | 148.0G / 4.0s/it | 162.0G / 4.5s/it | - | - | - | |
| 14B | LoRA | 34.6G / 1.6s/it | 35.1G / 2.4s/it | 35.3G / 4.4s/it | 37.4G / 8.4s/it | 42.5G / 17.0s/it | 55.2G / 36.0s/it |
| LoRA (emb) | 51.2 / 1.7s/it | 51.1G / 2.6s/it | 51.5G / 4.6s/it | 54.1G / 8.6s/it | 56.8G / 17.2s/it | 67.7G / 36.3s/it | |
| Q-LoRA | 18.7G / 5.3s/it | 18.4G / 6.3s/it | 18.9G / 8.2s/it | 19.9G / 11.8s/it | 23.0G / 20.1s/it | 27.9G / 38.3s/it | |
| 72B | LoRA + Deepspeed Zero3 | 215.4G / 17.6s/it | 217.7G / 20.5s/it | 222.6G / 29.4s/it | 228.8G / 45.7s/it | 249.0G / 83.4s/it | 289.2G / 161.5s/it |
| Q-LoRA | 61.4G / 27.4s/it | 61.4G / 31.5s/it | 62.9G / 41.4s/it | 64.1G / 59.5s/it | 68.0G / 97.7s/it | 75.6G / 179.8s/it | |
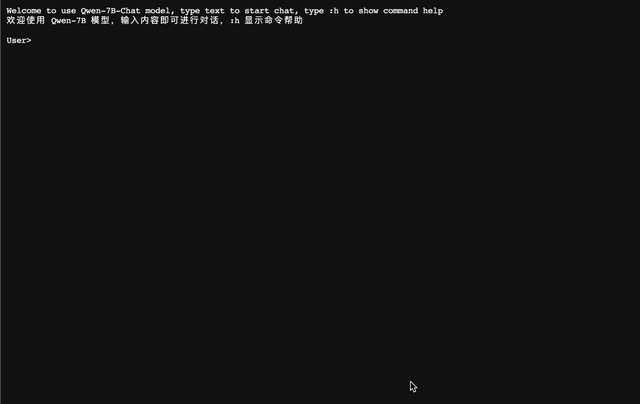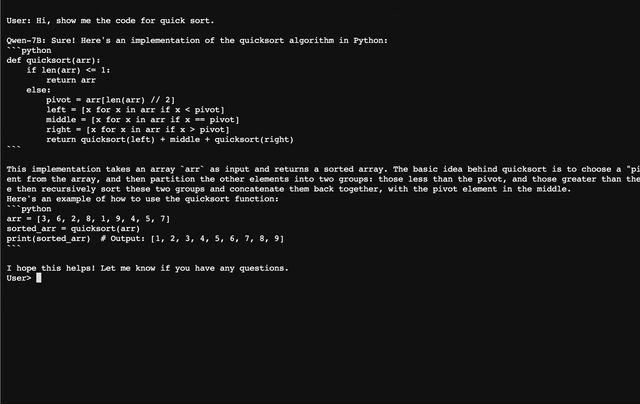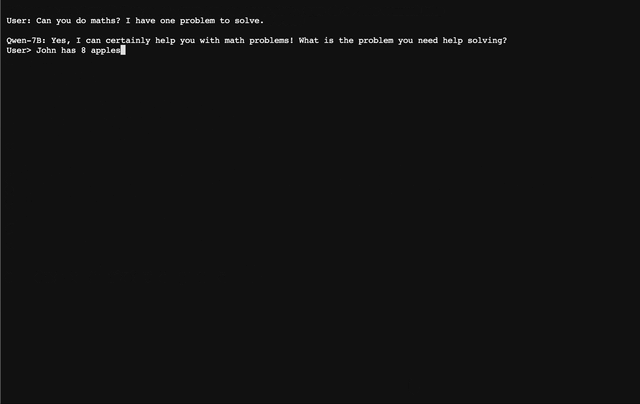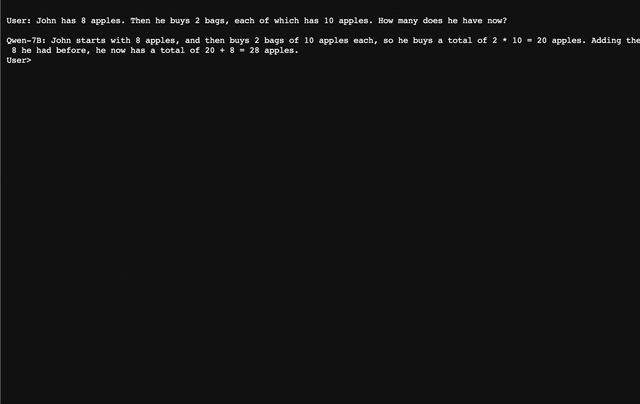
### CLI デモ `cli_demo.py` に CLI のデモ例を用意しています。ユーザはプロンプトを入力することで Qwen-7B-Chat と対話することができ、モデルはストリーミングモードでモデルの出力を返します。以下のコマンドを実行する: ``` python cli_demo.py ```
### API
OpenAI API をベースにローカルAPIをデプロイする方法を提供する(@hanpenggit に感謝)。始める前に、必要なパッケージをインストールしてください:
```bash
pip install fastapi uvicorn "openai<1.0" pydantic sse_starlette
```
それから、API をデプロイするコマンドを実行します:
```bash
python openai_api.py
```
チェックポイント名やパスには `-c`、CPU デプロイメントには `--cpu-only` など、引数を変更できます。API デプロイメントを起動する際に問題が発生した場合は、パッケージを最新バージョンに更新することで解決できる可能性があります。
API の使い方も簡単です。以下の例をご覧ください:
```python
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
# ストリーミングレスポンスを有効化するリクエストを作成する
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
# ストリーミング出力形式でのストップワードの指定はまだサポートされておらず、開発中です。
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
# ストリーミングレスポンスを有効化しないリクエストを作成する
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=False,
stop=[] # 例えば、stop=["Observation:"] (ReAct プロンプトの場合)。
)
print(response.choices[0].message.content)
```

**Function Calling** もサポートされています(ただし、今のところ `stream=False` の場合のみ)。使用例](examples/function_call_examples.py) を参照してください。
## 🐳 Docker
デプロイプロセスを簡素化するために、あらかじめ環境を構築した docker イメージを提供しています: [qwenllm/qwen](https://hub.docker.com/r/qwenllm/qwen)。ドライバを導入し、モデルファイルをダウンロードするだけで、デモを起動し、OpenAI APIをデプロイし、モデルを微調整することができます。
### 準備
1. 使用するイメージに応じて、正しいバージョンのNvidiaドライバをインストールしてください:
- `qwenllm/qwen:cu117` (**recommend**): `>= 515.48.07`
- `qwenllm/qwen:cu114` (w/o flash-attention): `>= 470.82.01`
- `qwenllm/qwen:cu121`: `>= 530.30.02`
- `qwenllm/qwen:latest`: same as `qwenllm/qwen:cu117`
2. [Docker](https://docs.docker.com/engine/install/) と [nvidia-container-toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html) をインストールして設定します:
```bash
# configure docker
sudo systemctl start docker
# test if docker is correctly installed
sudo docker run hello-world
# configure nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# test if nvidia-container-toolkit is correctly installed
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
```
3. モデルのチェックポイントとコードを環境にダウンロードします([こちら](#DownloadModel)を参照)。
### デプロイ
ここでは例として Qwen-7B-Chat を使用する。ウェブ・デモや API を起動する前に、以下のように設定を行います:
```bash
IMAGE_NAME=qwenllm/qwen:cu117
PORT=8901
CHECKPOINT_PATH=/path/to/Qwen-7B-Chat # Path to downloaded model checkpoints and codes
```
以下のスクリプトがビルドに役立つ:
* OpenAI API
```bash
bash docker/docker_openai_api.sh -i ${IMAGE_NAME} -c ${CHECKPOINT_PATH} --port ${PORT}
```
* Web UI
```bash
bash docker/docker_web_demo.sh -i ${IMAGE_NAME} -c ${CHECKPOINT_PATH} --port ${PORT}
```
* CLI Demo
```bash
bash docker/docker_cli_demo.sh -i ${IMAGE_NAME} -c ${CHECKPOINT_PATH}
```
上記のコマンドは自動的に必要なイメージをダウンロードし、バックグラウンドでWeb UIデモを起動します(サービスは自動で再起動します)。デモを使用するには、ホスト上で `http://localhost:${PORT}` を開いてください。
以下の出力が表示されれば、デモは正常に起動しています:
```text
Successfully started web demo. Open '...' to try!
Run `docker logs ...` to check demo status.
Run `docker rm -f ...` to stop and remove the demo.
```
デモの状態を確認したい場合は、`docker logs qwen` を使って出力を表示できる。
docker rm -f qwen` でサービスを停止し、コンテナを削除できる。
### ファインチューニング
ビルド済みのDockerイメージを利用したファインチューニングの方法は、基本的に[前章](#Finetuning)と同じです(すでにイメージに依存関係がインストールされています):
以下はシングルGPUのLoRAの例です:
```bash
IMAGE_NAME=qwenllm/qwen:cu117
CHECKPOINT_PATH=/path/to/Qwen-7B # Path to downloaded model checkpoints and codes
#CHECKPOINT_PATH=/path/to/Qwen-7B-Chat-Int4 # Path to downloaded model checkpoints and codes (Q-LoRA)
DATA_PATH=/path/to/data/root # Prepare finetune data at ${DATA_PATH}/example.json
OUTPUT_PATH=/path/to/output/checkpoint # Path to finetune outputs
# Use all host devices by default
DEVICE=all
# If you need to specify GPUs for training, set device as follow (NOTE: internal quotation marks cannot be omitted)
#DEVICE='"device=0,1,2,3"'
mkdir -p ${OUTPUT_PATH}
# Single-GPU LoRA finetuning
docker run --gpus ${DEVICE} --rm --name qwen \
--mount type=bind,source=${CHECKPOINT_PATH},target=/data/shared/Qwen/Qwen-7B \
--mount type=bind,source=${DATA_PATH},target=/data/shared/Qwen/data \
--mount type=bind,source=${OUTPUT_PATH},target=/data/shared/Qwen/output_qwen \
--shm-size=2gb \
-it ${IMAGE_NAME} \
bash finetune/finetune_lora_single_gpu.sh -m /data/shared/Qwen/Qwen-7B/ -d /data/shared/Qwen/data/example.json
```
例えばシングルGPUのQ-LoRAに変更するには、`docker run`内のbashコマンドを変更するだけでいい:
```bash
bash finetune/finetune_qlora_single_gpu.sh -m /data/shared/Qwen/Qwen-7B-Chat-Int4/ -d /data/shared/Qwen/data/example.json
```
## 🔥 システムプロンプト
Qwen-1.8-Chat と Qwen-72B-Chat は、複数回の複雑な対話を伴う多様なシステム プロンプトで完全にトレーニングされているため、さまざまなシステム プロンプトに従い、コンテキストに応じたモデルのカスタマイズを実現し、Qwen-Chat のスケーラビリティをさらに向上させることができます。
システム プロンプトを使用すると、Qwen-Chat は **ローリー プレイ**、**言語スタイルの転送**、**タスク設定**、**動作設定**を実現できます。


詳細については、[サンプルドキュメント](examples/system_prompt.md)を参照してください。
## ツールの使用
Qwen-Chat は、ツールの使用法と関数呼び出し機能に合わせて最適化されています。 ユーザーはエージェント、LangChain アプリケーションを開発し、Python コード インタープリターで Qwen を拡張することもできます。
ReAct プロンプトの原則に基づいてツール呼び出しを実装する方法に関するドキュメントを提供しています。[ReAct の例](examples/react_prompt.md) を参照してください。 この原則に基づいて、[openai_api.py](openai_api.py) で関数呼び出しのサポートを提供します。
オープンソースの中国語評価ベンチマークでモデルのツール呼び出し機能をテストしたところ、Qwen-Chat が一貫して良好なパフォーマンスを発揮することがわかりました。
| Chinese Tool-Use Benchmark (Version 20231206) | |||
|---|---|---|---|
| Model | Tool Selection (Acc.↑) | Tool Input (Rouge-L↑) | False Positive Error↓ |
| GPT-4 | 98.0% | 0.953 | 23.9% |
| GPT-3.5 | 74.5% | 0.807 | 80.6% |
| Qwen-1_8B-Chat | 85.0% | 0.839 | 27.6% |
| Qwen-7B-Chat | 95.5% | 0.900 | 11.6% |
| Qwen-14B-Chat | 96.9% | 0.917 | 5.6% |
| Qwen-72B-Chat | 98.2% | 0.927 | 1.1% |
| Code Interpreter Benchmark (Version 20231206) | ||||
|---|---|---|---|---|
| Model | Accuracy of Code Execution Results (%) | Executable Rate of Code (%) | ||
| Math↑ | Visualization-Hard↑ | Visualization-Easy↑ | General↑ | |
| GPT-4 | 82.8 | 66.7 | 60.8 | 82.8 |
| GPT-3.5 | 47.3 | 33.3 | 55.7 | 74.1 |
| LLaMA2-13B-Chat | 8.3 | 1.2 | 15.2 | 48.3 |
| CodeLLaMA-13B-Instruct | 28.2 | 15.5 | 21.5 | 74.1 |
| InternLM-20B-Chat | 34.6 | 10.7 | 25.1 | 65.5 |
| ChatGLM3-6B | 54.2 | 4.8 | 15.2 | 67.1 |
| Qwen-1.8B-Chat | 25.6 | 21.4 | 22.8 | 65.5 |
| Qwen-7B-Chat | 41.9 | 23.8 | 38.0 | 67.2 |
| Qwen-14B-Chat | 58.4 | 31.0 | 45.6 | 65.5 |
| Qwen-72B-Chat | 72.7 | 41.7 | 43.0 | 82.8 |

## 長い文脈の理解
コンテキスト長を拡張し、トレーニング シーケンス長のボトルネックを解消するために、NTK 対応補間、ウィンドウ アテンション、LogN アテンション スケーリングなどのいくつかの技術を導入し、Qwen-14B のコンテキスト長を 2K から 8K 以上に拡張します。 トークン、および Qwen-1.8B/7B は 8K から 32K トークンまで。
Qwen-72B では、より大きな回転ベースを備えたより長いコンテキストに RoPE を適応させます。 Qwen-72B は、32K トークンの最大コンテキスト長をサポートします。
私たちは、PPL 評価を使用して arXiv データセットで言語モデリング実験を実施し、Qwen が長いコンテキストのシナリオで優れたパフォーマンスを達成できることを発見しました。 結果を以下に示します。
| Model | Sequence Length | |||||
|---|---|---|---|---|---|---|
| 1024 | 2048 | 4096 | 8192 | 16384 | 32768 | |
| Qwen-7B (original) | 4.23 | 3.78 | 39.35 | 469.81 | 2645.09 | - |
| + dynamic_ntk | 4.23 | 3.78 | 3.59 | 3.66 | 5.71 | - |
| + dynamic_ntk + logn | 4.23 | 3.78 | 3.58 | 3.56 | 4.62 | - |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.78 | 3.58 | 3.49 | 4.32 | - |
| Qwen-1.8B | 5.00 | 4.48 | 4.13 | 3.89 | 17.42 | 433.85 |
| + dynamic_ntk + logn + window_attn | 5.00 | 4.48 | 4.14 | 3.93 | 3.82 | 3.83 |
| Qwen-7B | 4.23 | 3.81 | 3.52 | 3.31 | 7.27 | 181.49 |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.81 | 3.52 | 3.33 | 3.22 | 3.17 |
| Qwen-14B | - | 3.46 | 22.79 | 334.65 | 3168.35 | - |
| + dynamic_ntk + logn + window_attn | - | 3.46 | 3.29 | 3.18 | 3.42 | - |
| Qwen-72B | - | - | - | 2.83 | 2.73 | 2.72 |
{kind=link}